現在想標題越來越困難了...今天就 Copy 一下昨天的標題吧!
昨天大致介紹了幾個不同的 EdgeAI 工具,今天要來分享一下 ST Edge AI Developer Cloud 這個工具的使用方式~
前幾天有說到,STM32 相關的 EdgeAI 工具有很多,而 X-CubeMX.AI 是 CubeMX 的延伸插件,能夠快速整合 CubeMX 使用,但是如果今天在電腦上沒有載 CubeMX,又或是只需要產出一個模型的 Library 就好,ST 也提供了雲端工具,也就是今天要介紹的 ST Edge AI Developer Cloud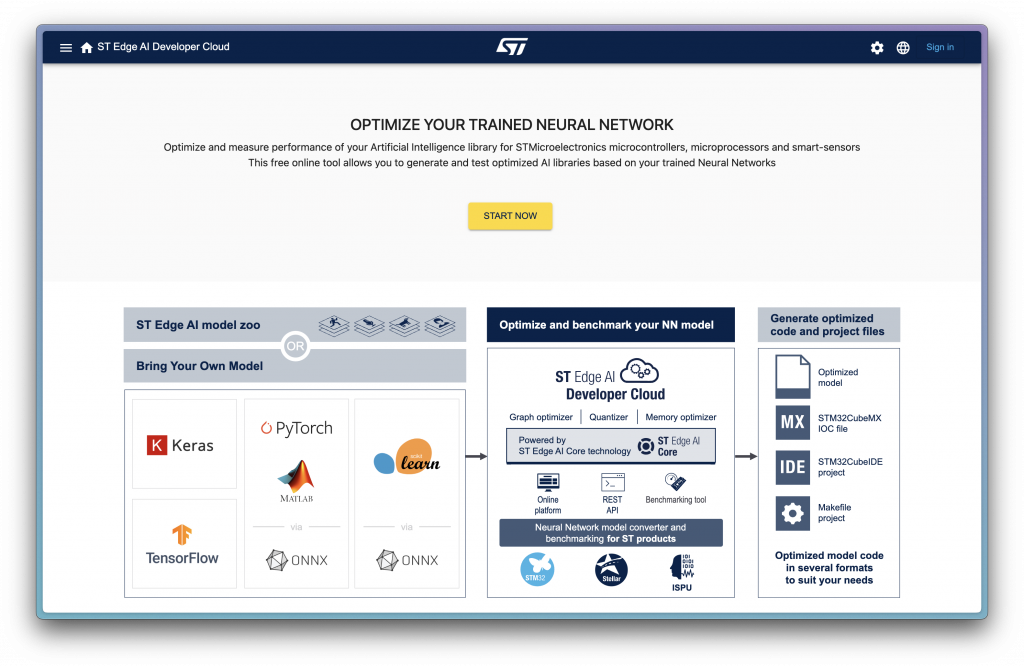
使用這個服務會需要建立一個帳戶,這個帳戶會記錄你上傳的所有 Model 和 Optimize 後的資料。
當登入後,會看到這個頁面: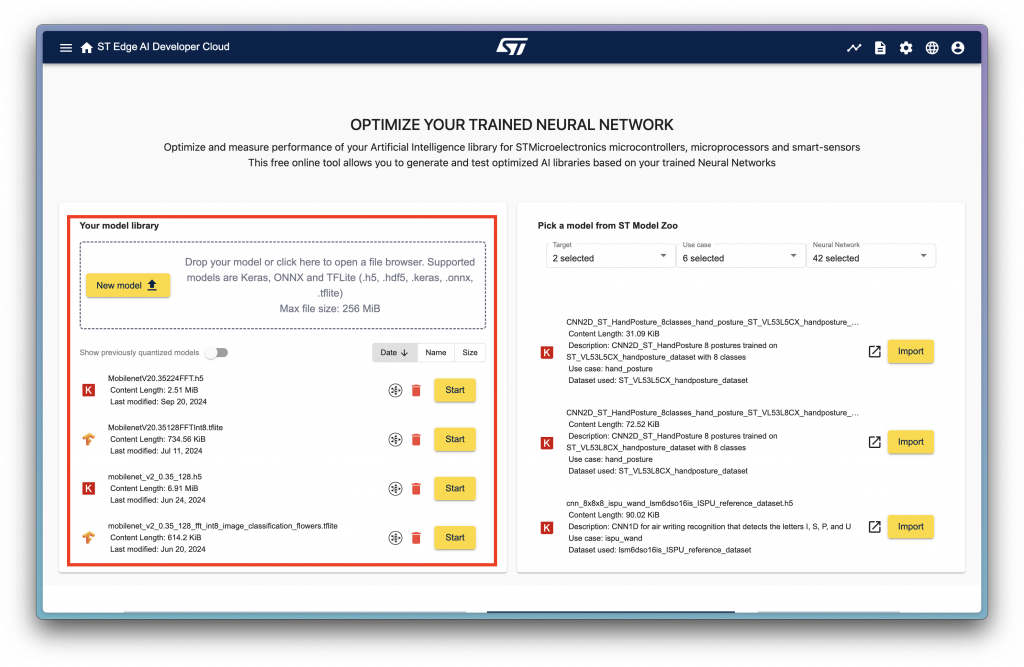
左邊紅框框住的地方是可以上傳自己 Custom Model 的地方,而右邊則是可以選擇 ST 提供的 Model;當有上傳過資料以後,左邊就過去使用過的模型資料。
這次示範使用 ST-Model Zoo 下載的 MobileNetV2-0.35-224 Food101 FFT 作為示範,此模型相關訊息如下:
因為等等也想要示範訓練後量化(post training quantization) 的效果,因此這邊使用的是 float32 的模型版本。
當上傳模型後就可以按下 Start 選擇進入下一步: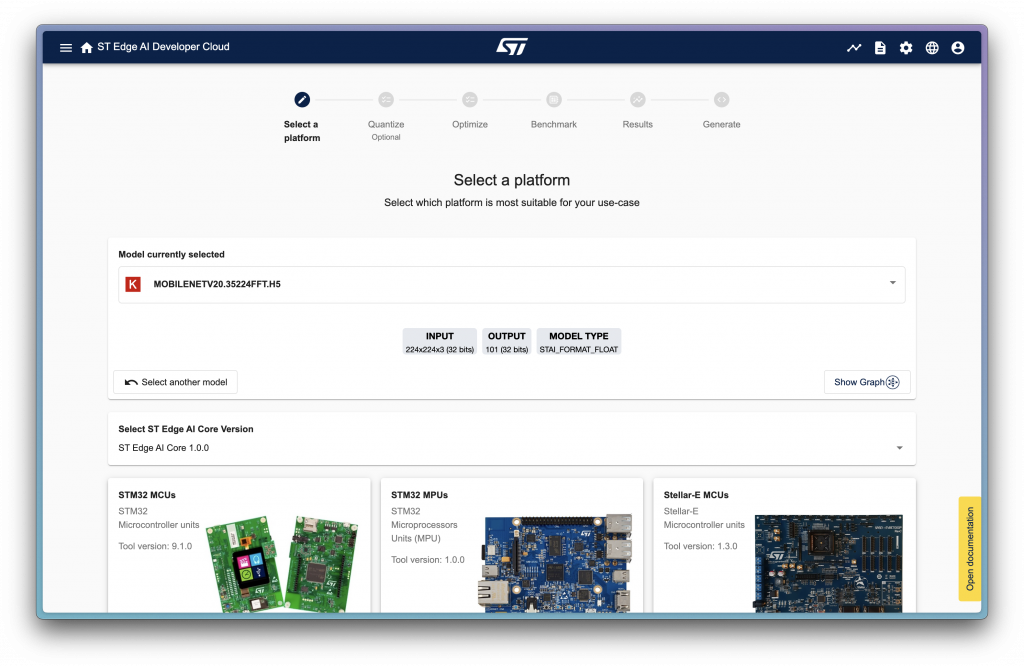
這邊會選擇你的目標平台是什麼,因為接下來會使用 STM32U585 進行開發,因此選擇 MCU 做為目標。
選完以後會到量化的階段,這也是一開始為什麼先選擇 float32 model 的原因,因為才會有這個量化階段的選擇。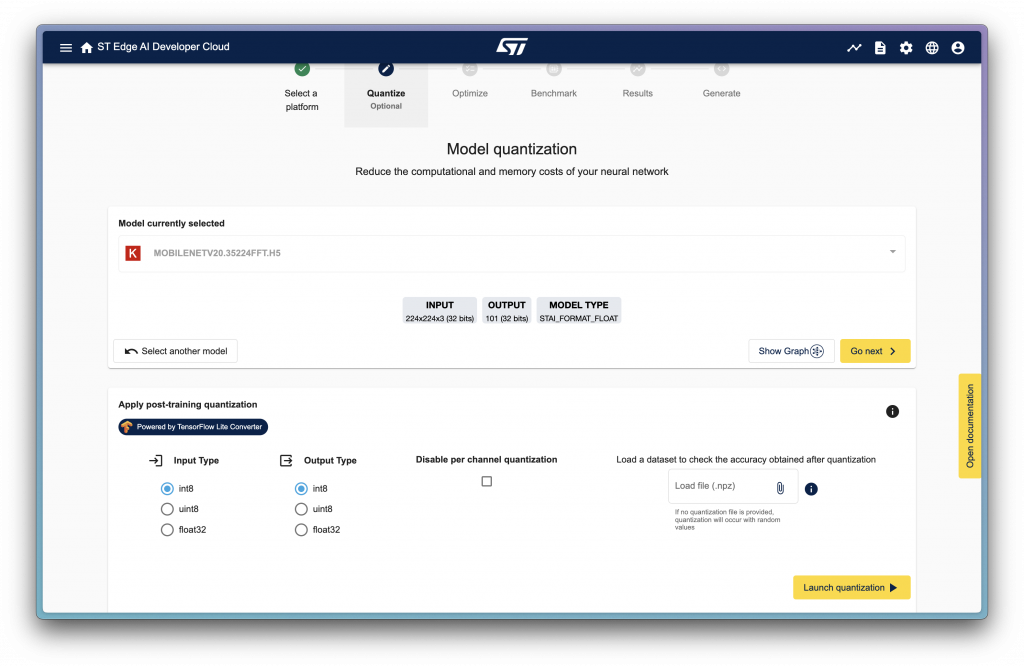
這邊可以看到可以選擇量化輸入輸出的格式,以及兩個選項分別為 Disable per channel quantization 和 Load a dataset to check the accuracy obtained after quantization。
Load dataset 主要是可以去進行 validation,今天先跳過不講,而 per channel quantization 是在進行量化時並不是對整個 Tensor 進行量化,而是分開 Channel 進行量化,詳細的內容之後有機會再展開講講(?
這邊先給出結論,當勾選出 Disable per channel quantization 時降低最後產出的 Flash Memory Size 以及推理時所需的 RAM size,但是推理速度也會因此提高。
這邊都不做任何改動直接進行量化,量化以後可以看到底下會出現量化過的 Model 結果(所有過去量化的結果都會存在這裡)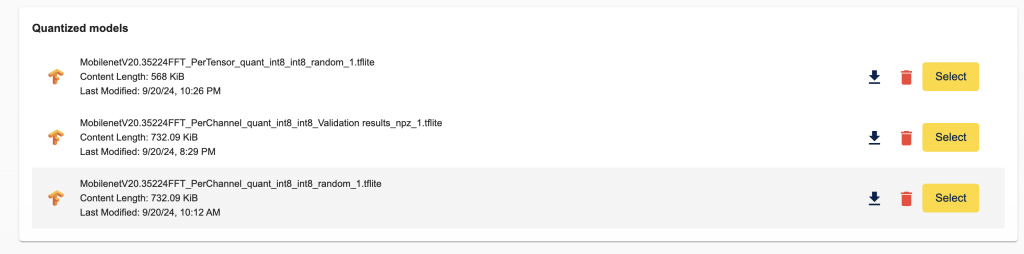
這邊選擇自己量化的結果以後可以下一步,就可以來到優化的環節: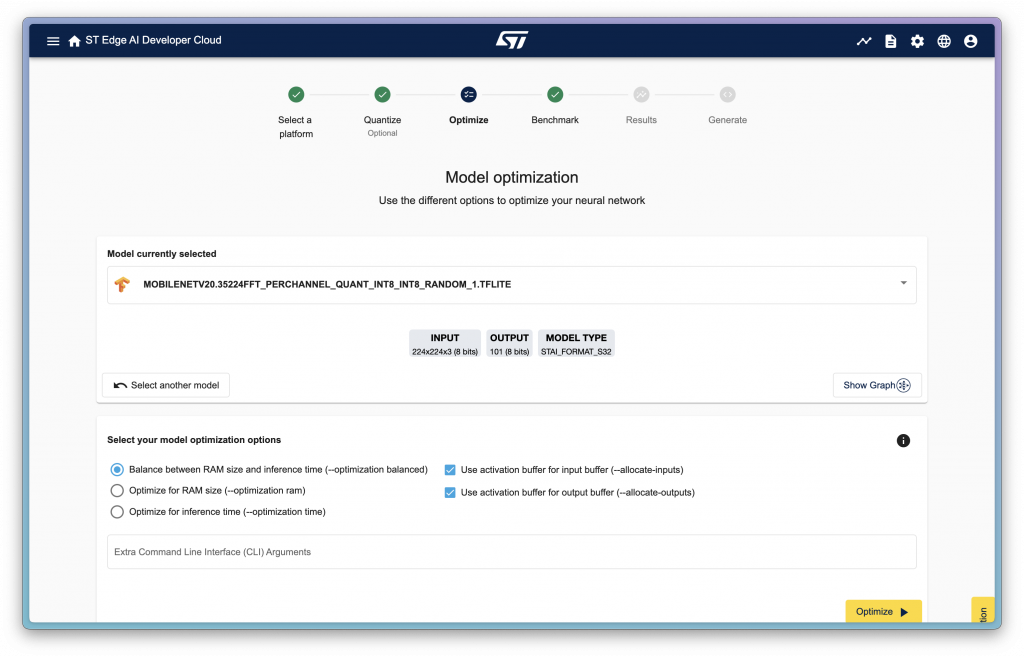
這邊左邊三個選項是可以選擇是要根據 RAM 使用大小優化、根據推理時間優化、或是平衡優化,而右邊的兩個選項則是當勾選以後,input/output buffer 會在下一次推理開始時被覆寫,因此不會保留先前的結果,勾選後能減少記憶體使用量。
這邊依然都勾選以後進行 optimize,之後可以看到底下會有幾個結果,這邊稍微展開看幾個不同的設定產生的結果:



這邊我們進入下一步 Benchmark 的階段,這邊可以讓你選擇不同的 STM32 開發板進行 Benchmark,讓你初步對推理結果有點概念。這邊我們選擇 U585 開發板以後進行 Benchmark,結果如下:
如果在上面是選擇 Disable per channel quantization 的話這邊的推理速度會是 1120ms 左右。
Benchmark 其實是可選的步驟,如果不想等待也可以直接按下一步到 result 的步驟,這邊就可以匯出一些中途不同變量的結果成圖表,供後續比較使用。而再下一步就可以進到產出的部分了,這邊就要選擇實際要輸出的目標晶片以及開發板是什麼,如下圖: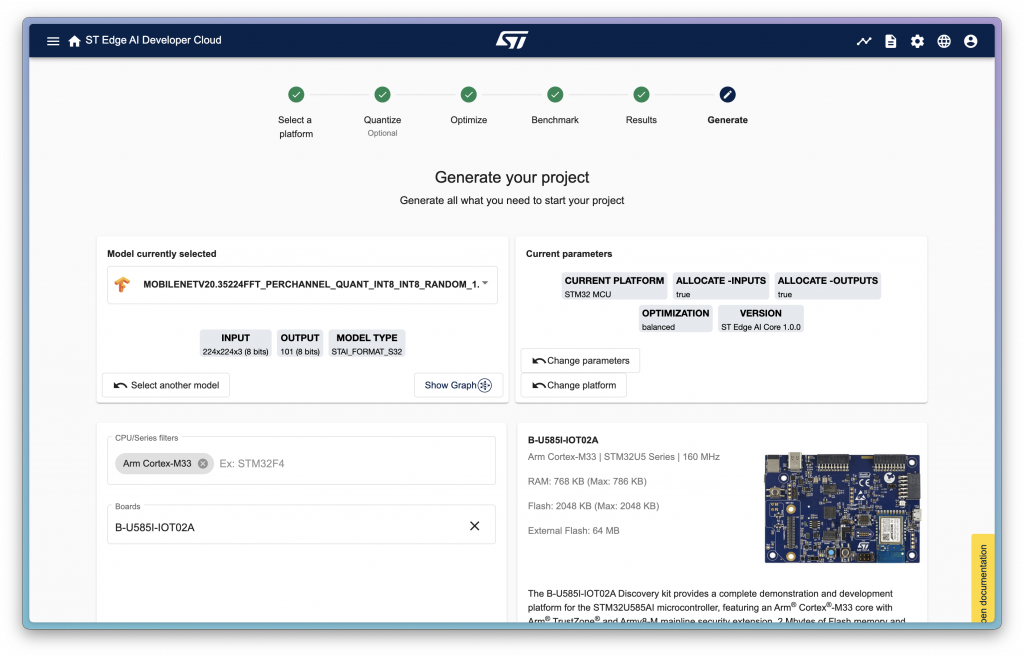
選好以後就可以選擇四個不同的選擇進行輸出,由左至右分別為:
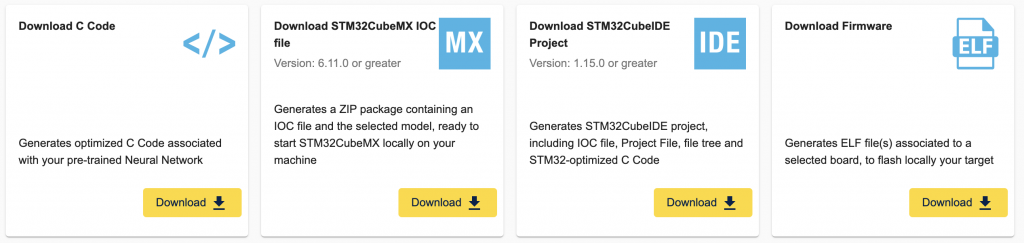
到這邊基本上就可以算是完成了,就會得到一份轉成 C code 並且執行 ST EdgeAI Library 的程式,或是根據你手上如果有開發板的話也可生成 Firmware 以後燒錄進行測試。
但如果我們就是要自己寫 code 控制,不單單只想用範例 Firmware 呢?那就是之後會繼續分享到的~
今天就先到這邊~明天準時時間(應該)在同一頻道(?相會~

